The Case Against an AI Chatbot in EMS

Protocols are legal documents. Large language models are not.
Picture a paramedic in the back of a moving ambulance. The patient is a five-year-old with a femur fracture, screaming, scared, and in pain. Fentanyl has already been given and the pain is not controlled. The medic opens an app and voices a text into a chatbot, asking for a pediatric ketamine dose. A paragraph of text comes back. It sounds confident. It sounds clinical. It might even be correct.
But the medical director who signed the protocol document for that agency has never seen those exact words, in that exact order, with that exact reasoning attached. In 21 states, the document is signed not by an agency medical director but by the state medical director, with the force of statute and administrative rule behind it. Either way, in that moment, the legal architecture of EMS quietly comes apart.

This is the question I keep coming back to as I watch large language model chatbots get pitched to EMS leaders. Not whether the technology is impressive. It is. Not whether it will eventually have a role in our field. It probably will. The question is whether the conversational chatbot, as a clinical interface, is the right tool for the back of an ambulance today. I do not believe it is. And I think it is worth saying so plainly, because the gap between a polished demo and a safe deployment in EMS is wider than most people realize.
Let me say up front that I am not a skeptic of artificial intelligence. We use it across our teams every day. It is helping us with research, software development, quality assurance, and protocol review. It is genuinely transformative for non-patient-facing work, and I expect that footprint to keep growing. The question is not whether AI belongs in EMS. It does. It just does not belong in the seat of time-sensitive clinical decisions made on real patients. The reasons are structural, and they are worth walking through.

Start with what an EMS protocol actually is. In the rest of the house of medicine, clinical references are exactly that, references. An emergency physician operates under a license to practice medicine, with the standard of care and individual judgment as the framework. In EMS, the protocol is something different. It is a signed, dated, board-approved document that defines the legal scope of paramedic practice. A paramedic acting within the protocol is operating within their license. A paramedic acting outside the protocol is not. That document is reviewed by counsel, ratified by medical direction, and audited after the fact in QA review and, sometimes, in court.
This is what makes a protocol something more than a reference. It carries regulatory force where states have given it that weight. It defines the standard of care that a clinician will be measured against if something goes wrong. It is admissible as evidence and serves as the basis for expert testimony in court. And it shapes the scope of legal immunity that an EMS provider is entitled to when they act within it.

When a chatbot generates clinical guidance by paraphrasing, summarizing, or recombining protocol content, it produces text that no medical director has approved. The output looks authoritative because it is written in clinical language, but it does not carry the legal weight of the actual protocol. It is a paraphrase masquerading as policy. That distinction matters every time a paramedic acts on it, and it matters even more when something goes wrong and the case is reconstructed line by line.
The second problem is how these systems actually work. Large language models are probabilistic. They generate the next most likely token, then the next, then the next. That means the same question, asked twice, can produce two different answers. Hallucination is not a defect being engineered out. Researchers at the National University of Singapore formalized this mathematically and showed, using results from learning theory, that eliminating hallucination in large language models is not just difficult, it is impossible (Xu, Jain, and Kankanhalli, 2024). OpenAI‘s own 2025 research paper reached a parallel conclusion from a different direction. Hallucinations, they wrote, are a predictable outcome of how these systems are trained and evaluated, not a bug that better engineering will solve. The leading researchers in the field have largely stopped pursuing zero hallucination as a goal. The current consensus is managing uncertainty, not eliminating it.

The common rebuttal to all of this is that grounding the model to a specific document, in this case your agency’s protocol, solves the problem. It does not. Retrieval-augmented generation (RAG) reduces hallucination. It does not eliminate it. The model can still misread a protocol section, blend content from two similar pathways, or generate a clinically wrong sentence with complete confidence and no flag to the clinician. And there is a more dangerous finding tucked inside the OpenAI work. Models do not just get things wrong. They get things wrong confidently, with low expressed uncertainty and no signal that the answer deserves a second look. In a protocol-based system, where uncertainty should trigger a double-check, a tool that projects confidence it has not earned is not a safety net. It is a liability. In a domain where a misplaced decimal kills a child, “usually right” is not a category that exists.
None of this is to say all AI implementations in EMS are equivalent. Applications that surface medical-director-approved protocols through structured retrieval, with the source document directly referenced and the signed content the clinician sees, are doing something different from a chatbot that generates new sentences. The argument here is specifically about the conversational chatbot interface and the generative paraphrase that interface produces.
And there is a deeper problem that is less obvious from a demo. When I write an EMS protocol, I write it from top to bottom with intention. There is a progression. Assessment comes before intervention. Non-pharmacologic options come before drugs. Contraindications come before indications. First-line agents come before second-line. Doses come last, and only after the clinician has been walked through the decision that justifies them. The protocol is not a flat database of facts. It is a structured pathway, and the order is part of the clinical content written and approved by a physician.

A chatbot does not see that. When a medic types “pain dose for a five-year-old,” the model treats the protocol as a searchable text corpus, finds the line that matches, and returns it. Every step that came before that line, the assessment, the contraindications, the alternative agents, the recognition that this child might not need ketamine at all, becomes invisible. The clinician gets the answer to the question they asked, not the answer to the clinical situation they are managing.
Ketamine is the cleanest example. In a typical EMS system, ketamine appears in the analgesia protocol, the agitation protocol, the induction protocol, and sometimes in the bronchospasm pathway. Different doses. Different routes. Different concentrations. Different indications. Different contraindications. Ask a chatbot “what is the ketamine dose” and there is no good answer. Either the model picks one, in which case it is wrong roughly as often as it is right, or it lists all of them and asks the clinician to choose, in which case the burden of decision sits exactly where it should not.
That brings me to the operational point. The pitch for AI in EMS is almost always framed as cognitive load reduction. A paramedic working a critical patient is task-saturated. The argument goes that an intelligent assistant should reduce that load. I agree with the goal. I disagree that a chatbot is the way to get there.
A conversational interface, by design, asks the clinician to do work. Type a question. Wait for a paragraph. Read it. Parse it. Decide whether it applies to the protocol you are operating under. Reconcile the concentration the chatbot returned with the concentration on the truck. Choose between the three doses it offered. That is more cognitive load, not less, and it is being added at the worst possible moment, in a moving vehicle, with one hand, with bad lighting, with a sick patient who cannot wait. The right interface for the back of an ambulance is the one that gets the clinician to the right page, in the right protocol, in two taps, with no parsing required. Structured navigation removes work. Conversation adds it.
The final piece is accountability. Twenty years of serving as a medical expert in EMS cases has taught me that when something goes wrong, the case gets reconstructed line by line. Documentation is read aloud. Protocols are introduced as exhibits. Every decision is traced back to the person responsible for it. That chain of accountability is not a bureaucratic detail, it is the architecture that protects clinicians and patients alike.
Today, when a paramedic deviates from protocol, that chain holds. The deviation is documented. The medical director reviews the case. QA flags the variance. Education or remediation follows. The system learns. The clinician is supported. The patient is protected. It works because every step is traceable to a person who stands behind it.
When a chatbot produces a clinical recommendation, who is responsible for the output? The vendor disclaims it in the terms of service. The medical director never approved it. The paramedic acted on it in good faith because it appeared inside an app the agency adopted. If the recommendation contributed to a bad outcome, the chain breaks at exactly the moment it matters most. That is not a hypothetical concern. It is the structure of every malpractice case that will eventually be written about this technology.
All of which leads me to the part that bothers me most as a clinician and a scientist. The way we introduce new interventions into the house of medicine is well established. We define the outcome that matters. We run the trial. We look at the results. We let the data tell us whether the intervention helps, harms, or makes no difference. Then we decide. That discipline is not optional, and it does not change because the new intervention is software.

We have a clean recent example of what this looks like when it is done right. The Copenhagen Emergency Medical Services group ran a double-masked randomized trial of a machine learning model designed to help dispatchers recognize out-of-hospital cardiac arrest during 911 calls (Blomberg et al., JAMA Network Open, 2021). The trial enrolled more than 169,000 calls, including over a thousand confirmed cardiac arrests. The model worked. On the algorithmic metric, it outperformed the human dispatchers, with sensitivity of 85 percent compared to 77.5 percent. By the standard a vendor demo would use, that is a win.
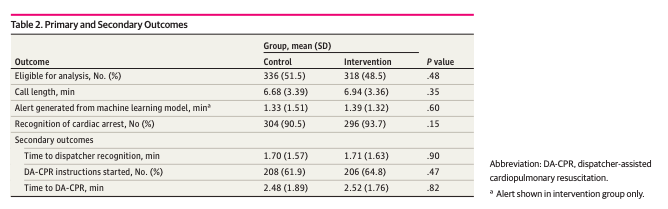
And yet, when the trial measured what actually mattered, whether dispatcher recognition of cardiac arrest improved when the AI was in the loop, there was no difference. The model was better at the task, the dispatchers had access to its alerts, and dispatcher performance did not change. The investigators were direct about it. They wrote that almost all decision support tools driven by artificial intelligence or machine learning have so far failed to improve outcomes in practice. The 2025 AHA guidelines reviewed this evidence and reached a measured conclusion. The technology is promising. It is not ready to be relied on.
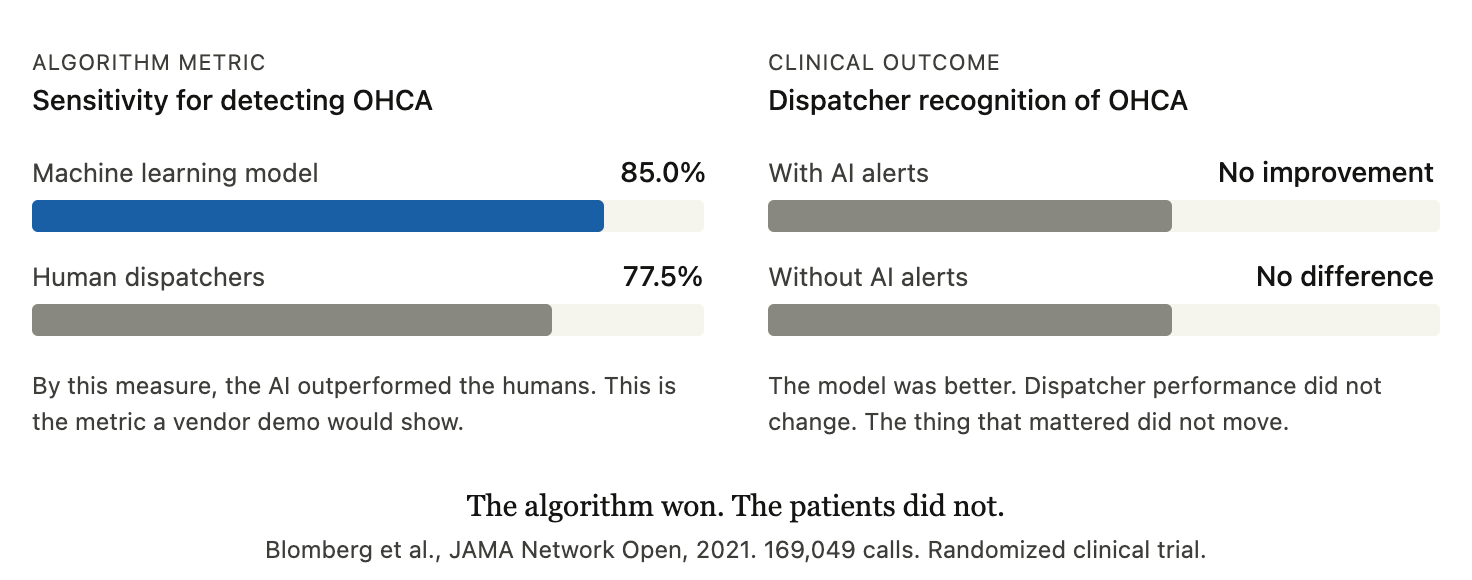
That is how this is supposed to work. We test our tools the way we test our drugs. We do not deploy them based on how good they look in the conference hall. The chatbot products being marketed to EMS today have not been studied with anything close to that rigor. There are no randomized trials. There are no patient-level outcomes. There are demos, testimonials, and screenshots. That is not enough.
None of this is an argument against artificial intelligence in EMS. There is real, serious work to be done in this space, and there are use cases where machine learning will help us deliver better care. The point is narrower than that. The conversational chatbot, as a clinical interface for paramedics making time-critical decisions on real patients, is the wrong form. The right form is curated, deterministic, auditable, and approved by the medical director who signs the protocol. The clinician sees the same content the medical director wrote, in the same order, with the same context, every single time.
EMS is not ready for an AI chatbot. Not because we are afraid of the technology, but because we are clinicians and scientists who understand what a protocol is and how new tools earn their place in our field. A protocol is a legal document, written with intention, designed to be navigated, not paraphrased. A new clinical tool is something we study before we deploy it, not after. Until the chatbot can honor both of those principles, the demo is the easy part. The deployment is where people get hurt.
Looking for AI Tools Your EMS Agency Can Actually Trust?
Get the technology. Skip the risk. Handtevy delivers purpose-built clinical decision support trusted by EMS agencies and Hospitals in all 50 states.
Schedule a Demo
About the Author

Peter Antevy, MD, FAEMS is a board-certified pediatric emergency medicine physician, EMS medical director, and the Founder and Chief Medical Officer of
Handtevy. He has spent his career focused on improving emergency care for both adults and children, with a particular emphasis on medication safety, resuscitation, and closing the gap between evidence-based medicine and what happens in the field and at the bedside.
Dr. Antevy serves as an EMS medical director in South Florida, where he oversees some of the busiest prehospital systems in the country. He is a nationally recognized speaker, researcher, and educator in emergency medicine, and has been instrumental in advancing pediatric readiness across EMS and hospital systems nationwide.
Through Handtevy, Dr. Antevy and his team support close to 3,000 EMS and hospital customers across all 50 states with purpose-built clinical decision support tools designed to reduce medication errors and improve outcomes during the most critical moments in patient care.
References
Blomberg SN, Christensen HC, Lippert F, et al. Effect of Machine Learning on Dispatcher Recognition of Out-of-Hospital Cardiac Arrest During Calls to Emergency Medical Services: A Randomized Clinical Trial. JAMA Network Open. 2021;4(1):e2032320.
Kupas DF, Schenk E, Sholl JM, Kamin R. Characteristics of Statewide Protocols for Emergency Medical Services in the United States. Prehospital Emergency Care. 2015;19(2):292-301.
Xu Z, Jain S, Kankanhalli M. Hallucination is Inevitable: An Innate Limitation of Large Language Models. arXiv. 2024;2401.11817.
OpenAI. Why Language Models Hallucinate. 2025.